Wprowadzenie
Czy kontroling musi być czasochłonny? Niekoniecznie. W czasach rosnącej ilości danych i potrzeby szybkiego reagowania, każda możliwość automatyzacji raportowania to skarb. Power Query, dostępne w Excelu i Power BI, jest narzędziem, które daje kontrolerom ogromną przewagę – pozwala raz przygotować proces przekształcania danych, a potem tylko jednym kliknięciem odświeżać raporty.
Kod, który dziś opisuję, to przykład bardzo praktycznego rozwiązania: automatyczne pobieranie, filtrowanie, łączenie i porządkowanie danych z wielu plików Excel. Przyda się wszędzie tam, gdzie co miesiąc lub tydzień trafiają do Ciebie pliki sprzedażowe do analizy. Jeśli chcesz, by Twoja praca była szybsza, dokładniejsza i bardziej efektywna – czytaj dalej.
Kontekst biznesowy
Wyobraź sobie, że co miesiąc otrzymujesz kilka, kilkanaście (a może i kilkadziesiąt) plików Excel z danymi o sprzedaży. Każdy z nich może zawierać dane z różnych regionów, w różnych formatach, z różnymi nazwami kolumn. Twoim zadaniem jest połączyć te dane w jedną całość, ustandaryzować formaty i stworzyć na ich podstawie raport. Brzmi znajomo? To codzienność wielu kontrolerów i analityków.
Ręczne kopiowanie danych, przekształcanie kolumn, szukanie braków czy nieścisłości – to nie tylko strata czasu, ale i potencjalne źródło błędów. Z pomocą przychodzi Power Query, który pozwala ten proces zautomatyzować i uprościć do maksimum.
1. Pobranie wszystkich plików z folderu
Pierwszym krokiem w kodzie jest wczytanie wszystkich plików z konkretnego folderu lokalnego. Używamy tutaj funkcji Folder.Files, która skanuje katalog i zbiera listę wszystkich znajdujących się w nim plików.
Source = Folder.Files("C:\Users\cezar\Downloads\excel")
Dzięki temu, nie musimy już ręcznie otwierać każdego pliku – wystarczy, że wkleimy go do folderu. Po odświeżeniu Power Query automatycznie go uwzględni w analizie. To ogromna oszczędność czasu – szczególnie przy powtarzalnych raportach miesięcznych.
2. Filtrowanie tylko plików sprzedażowych
W folderze mogą znajdować się inne pliki – notatki, inne raporty czy pliki tymczasowe. Dlatego drugi krok kodu to filtrowanie tylko tych plików, których nazwy zaczynają się od „sales_2025_” i kończą na „.xlsx”.
Filtered = Table.SelectRows(Source, each Text.StartsWith([Name], "sales_2025_") and Text.EndsWith([Name], ".xlsx"))
Ten prosty filtr zapewnia, że wczytamy tylko pliki, które faktycznie są danymi sprzedażowymi. Zmieniając fragment „sales_2025_” na inną nazwę, możemy łatwo dostosować kod do innych typów danych.
3. Wczytanie zawartości każdego pliku Excel
Każdy z wybranych plików jest następnie otwierany za pomocą funkcji Excel.Workbook. Dodajemy nową kolumnę „ContentTbl”, w której znajduje się zawartość danego pliku w postaci tabeli.
AddContent = Table.AddColumn(Filtered, "ContentTbl", each Excel.Workbook([Content], true))
To kluczowy moment – Power Query automatycznie rozpoznaje, co znajduje się w każdym pliku: nazwy arkuszy, ich zawartość i strukturę danych.
4. Rozwinięcie danych z arkuszy
Ponieważ każdy plik może zawierać kilka arkuszy, potrzebujemy „rozpakować” te dane – czyli uzyskać osobne wiersze dla każdego arkusza i jego zawartości.
Expand1 = Table.ExpandTableColumn(AddContent, "ContentTbl", {"Name","Data"}, {"SheetName","Data"})
Dzięki temu mamy jasność: z którego pliku i z jakiego arkusza pochodzi dana porcja danych. To przydatne przy analizie błędów lub weryfikacji poprawności danych.
5. Filtracja tylko poprawnych arkuszy
W poprzednim kroku mogliśmy trafić też na niepełne lub puste arkusze. Dlatego stosujemy filtrację, by zostawić tylko te, które faktycznie zawierają dane – gdzie nazwa arkusza nie jest pusta.
KeepOnlySheets = Table.SelectRows(Expand1, each [SheetName] <> null)
Ten krok zwiększa bezpieczeństwo całego procesu – dane, które nie nadają się do analizy, są od razu odrzucane. Dzięki temu unikamy błędów w dalszym etapie raportowania.
6. Rozwijanie danych z plików – kolumny sprzedażowe
Czas teraz na najważniejszy krok – wydobycie danych z arkuszy. Za pomocą funkcji Table.ExpandTableColumn rozwijamy zawartość kolumny „Data”, czyli faktyczne dane sprzedażowe. Tutaj wskazujemy konkretne kolumny, które nas interesują: „Date”, „SKU”, „Region”, „REGION”, „Channel”, „SalesValue”, „Netto” oraz „Volume”.
ExpandData = Table.ExpandTableColumn(
KeepOnlySheets,
"Data",
{"Date","SKU","Region","REGION","Channel","SalesValue","Netto","Volume"},
{"Date","SKU","Region","REGION","Channel","SalesValue","Netto","Volume"}
)
Ciekawym rozwiązaniem jest uwzględnienie podwójnych wersji kolumn – np. „Region” i „REGION”, czy „SalesValue” i „Netto”. To pokazuje, że dane pochodzą z różnych źródeł i mogą być nazwane różnie, ale niosą tę samą informację. Rozwijając je wszystkie, zyskujemy elastyczność – nie musimy martwić się, jak ktoś nazwał kolumnę w pliku.
Dzięki temu krokowi mamy już surowe dane sprzedażowe w jednym miejscu – gotowe do dalszej obróbki i standaryzacji.
7. Standaryzacja kolumn „Region”
Jednym z największych problemów przy łączeniu danych z wielu źródeł jest niejednolita nazwa kolumn. Często spotyka się sytuację, w której jeden plik zawiera kolumnę „Region”, a inny „REGION”. Obie oznaczają to samo, ale Power Query traktuje je jako osobne kolumny.
Dlatego kolejnym krokiem jest dodanie nowej kolumny „RegionStd”, która przyjmuje wartość z „Region”, a jeśli ta jest pusta – z „REGION”.
RegionStd = Table.AddColumn(
ExpandData, "RegionStd",
each if [Region] <> null then [Region] else [REGION],
type text
)
Dzięki temu mamy pewność, że kolumna „RegionStd” zawiera zawsze wartość, niezależnie od źródła danych. Możemy ją później spokojnie używać w analizach, filtrach czy grupowaniach – bez obaw, że coś „nie zadziała”.
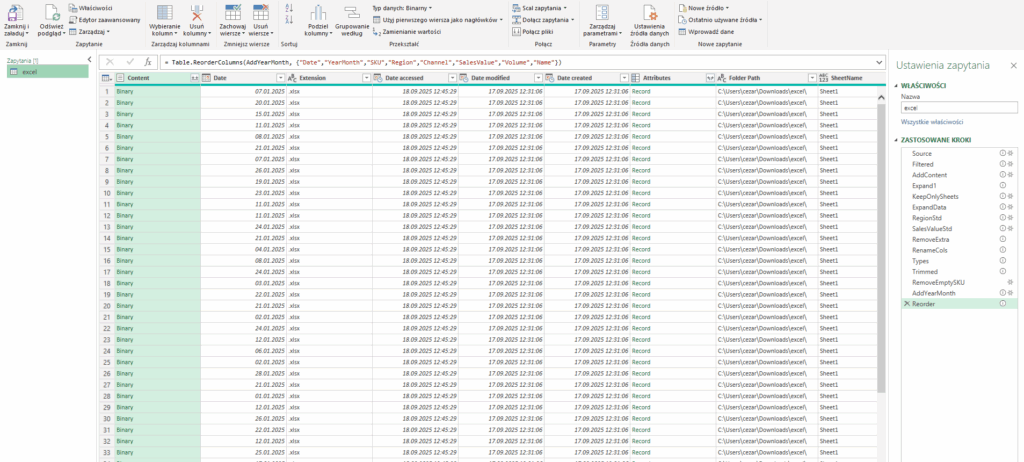
8. Ujednolicenie wartości sprzedaży
Podobna sytuacja dotyczy kolumn z wartością sprzedaży. W jednym pliku możemy mieć kolumnę „SalesValue”, w innym „Netto”. Obie opisują tę samą wielkość – wartość sprzedaży netto – ale znów, mają różne nazwy.
Dlatego tworzona jest nowa kolumna „SalesValueStd”, która przyjmuje wartość z jednej lub drugiej kolumny:
SalesValueStd = Table.AddColumn(
RegionStd, "SalesValueStd",
each if [SalesValue] <> null then [SalesValue] else [Netto],
type number
)
Dzięki temu wszystkie dane są ujednolicone – mamy jedną kolumnę, z którą pracujemy dalej. To kluczowe dla dalszego raportowania i agregowania danych.
9. Usunięcie nadmiarowych kolumn
Skoro już stworzyliśmy nowe, ujednolicone kolumny – nie potrzebujemy tych oryginalnych. Są tylko źródłem chaosu i mogą prowadzić do pomyłek. Dlatego usuwamy je:
RemoveExtra = Table.RemoveColumns(SalesValueStd, {"Region","REGION","SalesValue","Netto"})
To kolejny krok w stronę czystości i przejrzystości danych. W Power Query mniej znaczy więcej – im mniej kolumn, tym lepiej nam się z nimi pracuje.
10. Zmiana nazw kolumn na końcowe
Kiedy już mamy dane ustandaryzowane, warto nadać kolumnom właściwe, „finalne” nazwy. Robimy to za pomocą funkcji Table.RenameColumns:
RenameCols = Table.RenameColumns(RemoveExtra, {{"RegionStd","Region"},{"SalesValueStd","SalesValue"}})
W efekcie otrzymujemy kolumny o prostych i jednoznacznych nazwach: „Region” i „SalesValue”. To one będą wykorzystywane w dalszym raportowaniu, wykresach, tabelach przestawnych czy modelu danych Power BI.
11. Typowanie kolumn – porządek musi być
Dane z Excela często są traktowane przez Power Query jako tekst, nawet jeśli wyglądają jak liczby czy daty. To bywa frustrujące – chcesz np. zgrupować dane po miesiącach, a okazuje się, że kolumna „Date” jest tekstem. Dlatego jednym z najważniejszych kroków jest jawne zdefiniowanie typów danych dla każdej kolumny.
Types = Table.TransformColumnTypes(RenameCols, {
{"Date", type date},
{"SKU", type text},
{"Region", type text},
{"Channel", type text},
{"SalesValue", type number},
{"Volume", Int64.Type}
})
Dzięki temu zapewniamy, że:
- Date to faktyczna data (przydatna przy sortowaniu i grupowaniu),
- SKU, Region, Channel to teksty (czyli np. kody produktów, kanały sprzedaży),
- SalesValue i Volume to liczby, które można sumować, analizować i wizualizować.
Brak poprawnego typowania może prowadzić do dziwnych wyników w raportach – np. niemożności obliczenia sumy albo błędów przy łączeniu danych. Dlatego ten krok jest niezbędny.
12. Czyszczenie danych – puste SKU i niepotrzebne spacje
Czasami dane zawierają puste wiersze, błędne wpisy lub niepotrzebne spacje w kodach produktów (SKU). Te detale mogą wydawać się drobiazgami, ale w raportowaniu robią ogromną różnicę.
Najpierw usuwamy nadmiarowe spacje:
Trimmed = Table.TransformColumns(Types, {{"SKU", each if _ = null then null else Text.Trim(_), type text}})
Potem pozbywamy się wierszy, w których pole SKU jest puste – bo nie mają sensu analitycznego:
RemoveEmptySKU = Table.SelectRows(Trimmed, each [SKU] <> null and [SKU] <> "")
Po tych dwóch krokach mamy gwarancję, że dane są „czyste” – nie będą powodować błędów, nie będą zakłócać wizualizacji i analiz. Tego typu walidacje powinny być standardem w każdym modelu Power BI czy raporcie Excelowym.
13. Dodanie kolumny „RokMiesiąc” – idealne do grupowania
Kolejny krok to kolumna „YearMonth”, która wyciąga z daty tylko rok i miesiąc. Jest niezwykle przydatna przy analizie danych miesięcznych – np. przy porównaniach rok do roku (YoY) czy miesiąc do miesiąca (MoM).
AddYearMonth = Table.AddColumn(RemoveEmptySKU, "YearMonth", each Date.ToText([Date], "yyyy-MM"), type text)
Z tak przygotowaną kolumną można:
- szybko grupować dane po miesiącach,
- tworzyć wykresy z osią czasu,
- porównywać dynamikę sprzedaży.
To prosty trik, ale znacznie ułatwia pracę w raportach zarządczych i prezentacjach wyników.
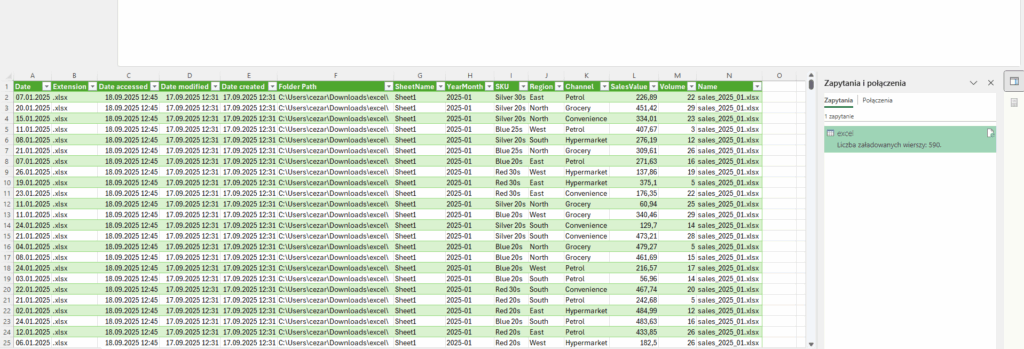
14. Kolejność kolumn – ergonomia ma znaczenie
Na koniec – porządkujemy kolumny w logicznej kolejności. Bo jeśli dane mają trafiać do odbiorców końcowych (zarząd, dział sprzedaży, controlling), muszą być przejrzyste i intuicyjne.
Reorder = Table.ReorderColumns(AddYearMonth, {"Date","YearMonth","SKU","Region","Channel","SalesValue","Volume","Name"})
Taka kolejność ułatwia czytanie danych: najpierw czas, potem produkt, region, kanał sprzedaży, a dopiero na końcu liczby i źródło pliku. Dobrze poukładana tabela to połowa sukcesu w raportowaniu.
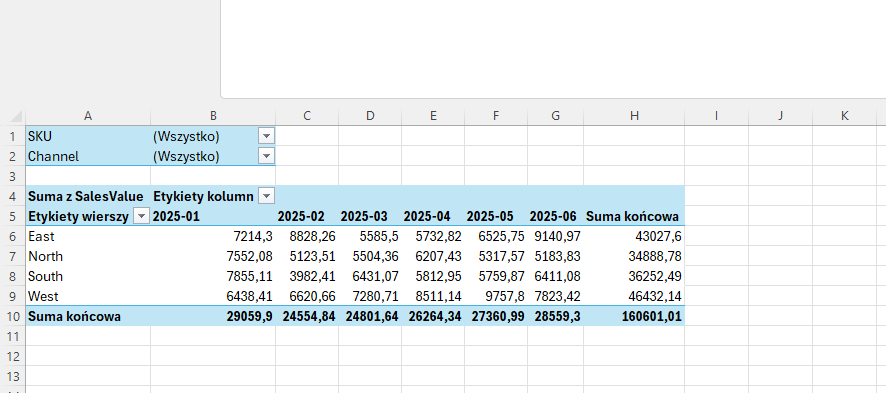
Korzyści z zastosowania Power Query w controllingu
Co nam daje taki kod? Przede wszystkim – oszczędność czasu. Zamiast ręcznie łączyć dane z dziesiątek plików, wystarczy wrzucić je do folderu i kliknąć „Odśwież”.
Ale to nie wszystko:
- Mniej błędów – automatyczne przekształcenia są bardziej niezawodne niż operacje ręczne.
- Większa skalowalność – kod działa niezależnie od liczby plików, regionów czy SKU.
- Transparentność procesu – każdy krok jest jawny, można go edytować lub dostosować.
- Łatwość wdrożenia – nie trzeba znać VBA ani programowania, wystarczy podstawowa znajomość Power Query.
To rozwiązanie może być fundamentem automatycznego dashboardu sprzedażowego w Power BI, raportu Excelowego lub miesięcznej analizy performance.
Zastosowanie w pracy controllera
Ten kod jest jak lojalny asystent – robi żmudną pracę za Ciebie. Zamiast godzin spędzonych na kopiowaniu danych i czyszczeniu formatów, możesz poświęcić czas na to, co naprawdę ważne: analizę, interpretację, rekomendacje.
W controllingu liczy się czas reakcji. Jeśli dane za sierpień masz gotowe już 1 września rano – jesteś o krok przed wszystkimi. Dzięki temu możesz szybciej wychwycić anomalie, podjąć działania korygujące lub lepiej zaplanować kolejny miesiąc.
W połączeniu z Power BI, dane te mogą automatycznie trafiać do interaktywnych dashboardów, które dział sprzedaży lub zarząd mogą przeglądać na bieżąco. To zupełnie nowy poziom raportowania.
Podsumowanie
Power Query to jedno z najpotężniejszych narzędzi w arsenale controllera. Dzięki prostemu, ale sprytnie napisanemu kodowi możesz zautomatyzować przetwarzanie danych z wielu plików, zyskać czystość i spójność danych oraz zbudować fundament pod szybkie i rzetelne raportowanie.
Ten konkretny przykład pokazuje, jak radzić sobie z różnicami w strukturze danych, jak łączyć dane z różnych plików i jak przygotować gotowe dane do analizy – wszystko w jednym kroku, bez ręcznego grzebania w plikach.



{kind=link}
{kind=link}