Wprowadzenie do tematu
W erze ogromnych zbiorów danych, gdzie każde kliknięcie i każda litera może mieć znaczenie, coraz częściej napotykamy problem niespójnych danych tekstowych. Czasem jeden drobny błąd w nazwie kontrahenta lub produktu potrafi całkowicie zrujnować analizę finansową czy sprzedażową. Dlatego właśnie warto znać i umieć stosować narzędzie, które pozwala na porównywanie ciągów znaków mimo drobnych różnic między nimi – mowa tu o równaniu Levenshteina.
Równanie to pozwala określić, jak bardzo dwa ciągi znaków różnią się od siebie – nie tylko czy są równe, ale jak bardzo są niepodobne. W świecie controllingu, gdzie dane są podstawą wszystkich decyzji, to narzędzie okazuje się bezcenne. Dzięki niemu możliwe staje się automatyczne dopasowywanie danych, które normalnie wymagałyby żmudnego sprawdzania ręcznego.
Co ciekawe, mimo że samo równanie ma już ponad pół wieku, jego przydatność w pracy z danymi dopiero teraz znajduje szerokie zastosowanie – szczególnie w połączeniu z językiem VBA, który jest nieodłącznym elementem pracy analityków w Excelu. Z tego artykułu dowiesz się, czym dokładnie jest odległość Levenshteina, jak powstała, na czym polega jej działanie oraz jak możesz wykorzystać ją w praktyce – dokładnie tak, jak robię to ja w mojej codziennej pracy w dużej firmie w dziale controllingu.
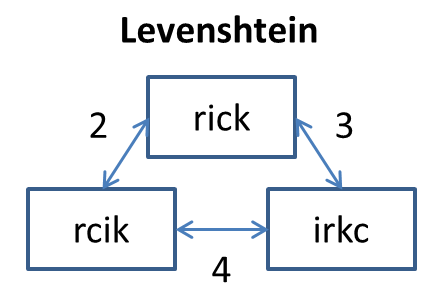
Krótkie wyjaśnienie pojęcia „odległość Levenshteina”
Zacznijmy od najważniejszego: czym właściwie jest ta cała „odległość Levenshteina”? Wyobraź sobie, że masz dwa słowa – na przykład „kot” i „kod”. Jak bardzo się różnią? Odpowiedź brzmi: jedną literą. Można więc powiedzieć, że ich odległość Levenshteina wynosi 1.
Odległość Levenshteina to liczba operacji, które musisz wykonać, by zmienić jeden ciąg znaków w drugi. Są trzy rodzaje operacji:
- Wstawienie znaku – np. z „ko” do „kot”
- Usunięcie znaku – np. z „koty” do „kot”
- Zamiana znaku – np. z „kot” do „kod”
Nie chodzi więc tylko o porównanie, czy ciągi są równe, ale o zmierzenie dystansu między nimi. To trochę jak mierzenie odległości między dwoma punktami na mapie – im więcej trzeba skręcać, omijać i iść naokoło, tym większa odległość.
Dlaczego to ważne? Bo w danych często pojawiają się literówki, inne formy zapisu (np. „Sp. z o.o.” vs „Spółka z o.o.”) albo błędy kopiowania. Dzięki odległości Levenshteina możemy wyłapać te przypadki i zautomatyzować ich obsługę.
Geneza równania Levenshteina
Równanie to zawdzięczamy radzieckiemu matematyczno-lingwistyce, Władimirowi Levenshteinowi, który opublikował je w 1965 roku. Co ciekawe, jego praca nie powstała w kontekście analizy danych czy Excela – wtedy nikt jeszcze nie śnił o takim zastosowaniu. Celem było raczej zrozumienie, jak błędy powstają w transmisji danych lub w języku naturalnym i jak je wykrywać.
To właśnie w komunikacji – tej cyfrowej i tej międzyludzkiej – pojawiały się problemy z przekłamaniami. Levenshtein chciał znaleźć sposób, by mierzyć, jak bardzo wiadomość różni się od oryginału, jeśli uległa zniekształceniu.
Dziś jego równanie jest wykorzystywane wszędzie – od algorytmów korekty pisowni, przez systemy rekomendacji, po rozpoznawanie mowy i tekstu. A jak się okazuje – również w Excelu i VBA, czyli w narzędziach pracy każdego controllera.
Dlaczego Levenshtein ma znaczenie w dzisiejszym świecie danych?
W pracy z danymi tekstowymi – szczególnie tymi pochodzącymi od różnych dostawców, systemów ERP, czy plików zewnętrznych – spójność jest jednym z największych problemów. Teoretycznie powinny być identyczne, ale praktycznie różnią się detalami:
- „Grupa ABC Sp. z o.o.” vs „ABC Sp. z o.o.”
- „Jan Kowalski” vs „Kowalski Jan”
- „Produkt123A” vs „Prod.123/A”
W takich przypadkach klasyczne porównania typu =A1=B1 zupełnie się nie sprawdzają. I tu właśnie pojawia się wartość algorytmu Levenshteina – pozwala wykryć, jak podobne są do siebie dwa teksty, niezależnie od ich dokładnego brzmienia.
W narzędziach takich jak Excel, w których operujemy na tabelach, setkach nazw i identyfikatorów, to nieoceniona funkcjonalność. A dzięki możliwościom, jakie daje VBA, można to narzędzie w pełni zautomatyzować i włączyć w codzienny workflow controllera.
evenshtein w VBA – implementacja w praktyce controllera
W mojej codziennej pracy controllera w dużej firmie, przetwarzam tysiące rekordów – raporty sprzedażowe, zestawienia z SAP, dane z CRM, pliki PDF eksportowane z różnych działów. Problem? Dane te bardzo często zawierają błędnie wpisane nazwy klientów, skróty, drobne różnice. Bez automatyzacji ich dopasowanie trwałoby godzinami.
Dlatego zaimplementowałem algorytm Levenshteina w VBA i używam go jako funkcji niestandardowej w Excelu. Dzięki temu mogę dla każdego wiersza określić, jak podobna jest dana nazwa do wzorcowej i – jeśli różnica jest niewielka – automatycznie ją zakwalifikować jako dopasowanie.
Struktura mojego kodu VBA z wykorzystaniem Levenshteina
Kod, którego używam, składa się z kilku kluczowych elementów. Oto ogólny przegląd:
- Funkcja
Levenshtein(s1 As String, s2 As String) As Long
To główna funkcja, która przyjmuje dwa ciągi znaków i zwraca ich odległość. - Tablica dwuwymiarowa
dist()
Reprezentuje matrycę porównań, w której przechowywana jest liczba operacji potrzebnych do przekształcenias1ws2. - Pętle
For
Porównują po kolei znaki z obu ciągów i zapisują wynik w macierzy. - Porównania znaków w
Mid(s1, i, 1)iMid(s2, j, 1)
To dzięki nim VBA „widzi”, które znaki trzeba zamienić, a które są identyczne. - Wynik końcowy
Levenshtein = dist(len1, len2)
Wartość znajdująca się w prawym dolnym rogu macierzy – to właśnie ta liczba mówi nam, jak bardzo dwa teksty się różnią.
Struktura jest czytelna, a cały kod działa bardzo wydajnie nawet przy setkach porównań w arkuszu. Wbudowując tę funkcję jako UDF (User Defined Function), mogę jej używać jak każdej innej funkcji w Excelu, np.:=Levenshtein(A2;B2)
To czyni z niej niezwykle elastyczne narzędzie do codziennej pracy analitycznej.
Z czego składa się kod VBA z Levenshteinem?
Oto uproszczona, ale w pełni funkcjonalna wersja kodu VBA, którego używam:
Function Levenshtein(s1 As String, s2 As String) As Integer
Dim i As Integer, j As Integer
Dim len1 As Integer, len2 As Integer
Dim dist() As Integer
Dim cost As Integer
len1 = Len(s1)
len2 = Len(s2)
ReDim dist(len1, len2)
For i = 0 To len1
dist(i, 0) = i
Next i
For j = 0 To len2
dist(0, j) = j
Next j
For i = 1 To len1
For j = 1 To len2
If Mid(s1, i, 1) = Mid(s2, j, 1) Then
cost = 0
Else
cost = 1
End If
dist(i, j) = Application.WorksheetFunction.Min( _
dist(i - 1, j) + 1, _
dist(i, j - 1) + 1, _
dist(i - 1, j - 1) + cost)
Next j
Next i
Levenshtein = dist(len1, len2)
End Function
Ten kod można wkleić do modułu VBA w Excelu i od razu używać jak standardowej funkcji. Co ważne, jest szybki i działa niezawodnie przy setkach wierszy. U mnie funkcja ta stała się fundamentem wielu innych automatyzacji.
Jak używam tego kodu w codziennej pracy?
Wyobraź sobie sytuację: mam miesięczny raport sprzedaży z systemu SAP, zawierający dane o kontrahentach, ich numerach klienta i wartościach faktur. Równolegle otrzymuję plik z działu handlowego, który zawiera ręcznie wprowadzone dane o klientach, ich planach zakupowych i prognozach. Problem? W obu plikach klienci są nazwani inaczej – raz jako „ABC Sp. z o.o.”, innym razem „ABC Spółka z o.o.” lub po prostu „ABC”.
Gdy próbuję zrobić klasyczne VLOOKUP, Excel nic nie znajduje – bo przecież dla Excela te nazwy to trzy różne teksty. Ręczne dopasowanie? Zajęłoby mi godziny.
Tu właśnie wchodzi algorytm Levenshteina. Dzięki niemu tworzę kolumnę, w której dla każdej nazwy z pliku A szukam najbardziej podobnej nazwy z pliku B. A dokładniej – liczę dystans Levenshteina pomiędzy daną nazwą a wszystkimi wierszami w drugiej tabeli, i wybieram tę z najmniejszą liczbą różnic.
Jeśli różnica wynosi 0 lub 1 – mam dopasowanie. Jeśli 2 lub 3 – przeglądam ręcznie tylko te pary. To już nie 1000 wierszy do przejrzenia, tylko może 10.
Na tym etapie często dodaję też mechanizm progów akceptacji. Ustalam, że np. jeżeli różnica w długości ciągów jest zbyt duża albo wynik przekracza 3, to traktuję wpis jako niedopasowany i go odrzucam. Taki filtr znacznie ogranicza liczbę fałszywych pozytywnych wyników.
Finalnie tworzę nowe kolumny w Excelu:
=Levenshtein(A2;B2)– liczy różnicę=IF(Levenshtein(A2;B2)<=2;"MATCH";"NO MATCH")– daje czytelny wynik=INDEX(...MATCH...)– automatycznie podaje wartość przypisaną do najlepszego dopasowania
Ten prosty mechanizm pozwala mi zautomatyzować coś, co normalnie wymagałoby kilku godzin żmudnego porównywania nazw ręcznie. A przecież w controllingu czas to pieniądz – im szybciej i dokładniej przygotuję dane, tym szybciej podejmowane są decyzje biznesowe.
Przykład praktyczny z życia controllera
Kilka miesięcy temu miałem projekt, który polegał na analizie odchyleń między zamówieniami klientów a faktyczną realizacją w magazynie. Dwa źródła danych – CRM z zamówieniami i SAP z dostawami – miały różne struktury. Najgorsze jednak było to, że… nazwy klientów się nie zgadzały. Niby ten sam kontrahent, ale w jednym systemie widniał jako „Firma X”, w drugim jako „X Sp. z o.o.”, a w trzecim jako „X POLSKA”.
Nie było szans, by zrobić tradycyjny JOIN w Power Query czy prostą tabelę przestawną. Każda próba kończyła się setkami niepowiązanych rekordów. Potrzebowałem sposobu, by szybko sprawdzić, które nazwy są do siebie na tyle podobne, że można je uznać za tę samą firmę.
Zastosowałem funkcję Levenshteina, którą wcześniej zaimplementowałem w Excelu. Dla każdego klienta z SAP porównywałem nazwę z CRM. Wyznaczałem „najbliższe dopasowanie” i budowałem nową tabelę korespondujących ze sobą nazw.
Efekt?
- 90% dopasowań było automatycznych (0–2 różnice)
- 7% wymagało minimalnej korekty ręcznej
- tylko 3% trzeba było obsłużyć od zera (nowe firmy lub totalnie błędne dane)
Dzięki temu nie tylko zaoszczędziłem czas, ale mogłem szybko przygotować rzetelny raport odchyleń, który bez Levenshteina byłby po prostu niemożliwy do wykonania w tak krótkim czasie.
Korzyści wynikające z wykorzystania algorytmu
Wykorzystanie algorytmu Levenshteina w codziennej pracy controllera przynosi szereg wymiernych korzyści. Przede wszystkim:
- Automatyzacja dopasowań – setki wierszy porównane w kilka sekund
- Redukcja błędów – eliminacja ręcznych literówek i niespójności
- Większa spójność danych – raporty, które łączą dane z wielu źródeł bez konfliktów
- Skrócenie czasu analizy – mniej czasu na „czyszczenie” danych, więcej na wnioski
- Możliwość skalowania – raz stworzony kod działa w każdym kolejnym projekcie
W mojej pracy był to game-changer. Wcześniej pół dnia zajmowało mi porządkowanie danych – teraz mam gotowe zestawienie w kilkanaście minut. I co ważniejsze – mogę być pewien jego dokładności.
Potencjał rozwoju i inne zastosowania w biznesie
Choć ja stosuję Levenshteina głównie w VBA i Excelu, to warto wiedzieć, że algorytm ten ma o wiele szersze zastosowania w świecie danych. Oto kilka przykładów:
- Analiza opinii klientów – grupowanie podobnych odpowiedzi w ankietach
- HR – porównywanie nazw stanowisk, kandydatów, umów
- Logistyka – dopasowanie kodów produktów lub nazw odbiorców
- Obsługa klienta – automatyczne wyszukiwanie zgłoszeń powiązanych z klientem, mimo literówek
- Integracja systemów – mapowanie danych między bazami, gdzie format zapisu jest różny
Co więcej, Levenshtein może być zintegrowany z Pythonem, SQL Serverem, Power BI – i wszędzie działa na tych samych zasadach. Dzięki temu firmy mogą budować bardziej inteligentne i odporne na błędy systemy analityczne.
Podsumowanie
Równanie Levenshteina to coś więcej niż tylko narzędzie informatyczne. To praktyczny sposób na rozwiązywanie realnych problemów z danymi, który sprawdza się doskonale w pracy controllera. Dzięki niemu dane z różnych źródeł mogą zostać skutecznie dopasowane i uporządkowane – nawet wtedy, gdy zawierają błędy, literówki czy różnice w zapisie.
W moim przypadku implementacja algorytmu w VBA otworzyła drzwi do automatyzacji wielu procesów, pozwoliła ograniczyć czas potrzebny na przygotowanie raportów i zwiększyła jakość analiz. Co więcej – jest to rozwiązanie dostępne dla każdego, bez potrzeby kupowania drogich narzędzi czy systemów klasy BI.
Jeśli pracujesz z danymi i zależy Ci na ich spójności, Levenshtein może okazać się jednym z najpotężniejszych narzędzi w Twoim arsenale.
Ciekawostka #1: Porównywanie z użyciem stopnia podobieństwa (np. 80%)
Choć klasyczna funkcja Levenshteina zwraca liczbę różniących się operacji, warto tę wartość przekształcić w coś bardziej intuicyjnego – procent podobieństwa. To szczególnie przydatne, gdy chcesz dynamicznie filtrować dopasowania, które mają np. minimum 80% zgodności z oryginałem.
Jak to działa?
Po obliczeniu odległości Levenshteina, możemy policzyć poziom podobieństwa jako:
similarity = (1 - (Levenshtein / Max(Len(s1), Len(s2)))) * 100
Na przykład:
- Dla dwóch słów, które mają długość 10 i różnią się 2 znakami:
similarity = (1 - 2 / 10) * 100 = 80%
W praktyce możesz w kodzie VBA dodać coś takiego:
If similarity >= 80 Then
' Traktuj jako dopasowanie
End If
To pozwala stworzyć elastyczne, bardziej „ludzkie” kryteria porównywania – zamiast sztywnego progu liczbowego.
Ciekawostka #2: Ograniczenie długości porównywanych ciągów do np. 15 znaków
Podczas pracy z dużymi plikami Excel, bardzo długie ciągi znaków (np. pełne opisy produktów, łańcuchy umów, komunikaty) mogą spowolnić działanie algorytmu – lub nawet doprowadzić do zawieszenia Excela, szczególnie gdy analiza dotyczy tysięcy komórek.
Aby tego uniknąć, dobrym pomysłem jest ograniczenie długości ciągów porównywanych do np. 15 pierwszych znaków – czyli najczęściej unikalnych fragmentów:
s1 = Left(s1, 15)
s2 = Left(s2, 15)
Dzięki temu skracasz czas działania funkcji nawet kilkukrotnie i znacząco ograniczasz ryzyko problemów z wydajnością, bez dużej straty jakości porównania (dla nazw firm i kontrahentów to najczęściej wystarczy).
Ciekawostka #3: Używaj Long, nie Integer, aby uniknąć błędu Stack Overflow
Domyślnie wielu użytkowników VBA używa typu Integer do deklaracji zmiennych sterujących (i, j, długości). Problem w tym, że Integer` ma zakres tylko od -32,768 do 32,767. Przy dłuższych tekstach i dużych macierzach może to doprowadzić do błędu Stack Overflow, który wyłącza kod i zamyka Excel.
Rozwiązanie? Zawsze deklaruj zmienne typu indeksującego jako Long:
Dim i As Long, j As Long
Dim len1 As Long, len2 As Long
To pozwala bezpiecznie operować na większych tablicach i zabezpiecza Twój kod przed krytycznymi błędami.
Zaktualizowany fragment kodu z tymi wskazówkami:
Function Levenshtein(s1 As String, s2 As String) As Double
Dim i As Long, j As Long
Dim len1 As Long, len2 As Long
Dim dist() As Long
Dim cost As Long
Dim similarity As Double
' Ogranicz długość do 15 znaków
s1 = Left(s1, 15)
s2 = Left(s2, 15)
len1 = Len(s1)
len2 = Len(s2)
ReDim dist(len1, len2)
For i = 0 To len1
dist(i, 0) = i
Next i
For j = 0 To len2
dist(0, j) = j
Next j
For i = 1 To len1
For j = 1 To len2
If Mid(s1, i, 1) = Mid(s2, j, 1) Then
cost = 0
Else
cost = 1
End If
dist(i, j) = WorksheetFunction.Min( _
dist(i - 1, j) + 1, _
dist(i, j - 1) + 1, _
dist(i - 1, j - 1) + cost)
Next j
Next i
' Zwróć procent podobieństwa
similarity = (1 - (dist(len1, len2) / WorksheetFunction.Max(len1, len2))) * 100
Levenshtein = Round(similarity, 2) ' np. 85.67%
End FunctionPodsumowanie ciekawostek:
| Wskazówka | Cel |
|---|---|
| Procent zgodności | Ocena podobieństwa w sposób zrozumiały dla użytkownika |
| Obcięcie do 15 znaków | Ochrona przed zawieszaniem Excela, szybsze działanie |
Deklaracja Long zamiast Integer | Uniknięcie Stack Overflow i awarii kodu VBA |
Te trzy proste usprawnienia znacząco zwiększają stabilność, szybkość i przydatność algorytmu Levenshteina w VBA – szczególnie w wymagających środowiskach finansowo-kontrolingowych, gdzie dokładność danych idzie w parze z efektywnością.


{kind=link}