Big O
W kontekście języka C, notacja Big O jest używana do określenia złożoności obliczeniowej algorytmów. Oznacza to, że Big O pozwala na oszacowanie, jak szybko algorytm rośnie wraz z rozmiarem danych wejściowych. Oto kilka przykładów zastosowania notacji Big O w języku C:
- Przeszukiwanie tablicy:
- Przeszukiwanie liniowe: O(n), gdzie n to liczba elementów w tablicy. Przeszukiwanie liniowe polega na sprawdzeniu każdego elementu w tablicy, aby znaleźć żądany element.
- Przeszukiwanie binarne (dla posortowanej tablicy): O(log n), gdzie n to liczba elementów w tablicy. Przeszukiwanie binarne polega na dzieleniu tablicy na połowę i sprawdzaniu, w której połowie znajduje się szukany element.
- Sortowanie tablicy:
- Sortowanie bąbelkowe: O(n^2), gdzie n to liczba elementów w tablicy. Sortowanie bąbelkowe porównuje sąsiednie elementy i zamienia je, jeśli są w złej kolejności, aż tablica zostanie posortowana.
- Sortowanie szybkie: O(n log n) w przypadku średnim, O(n^2) w najgorszym przypadku. Sortowanie szybkie dzieli tablicę na mniejsze części, sortuje je i łączy w jedną posortowaną tablicę.
- Operacje na listach jednokierunkowych:
- Wstawianie na początek listy: O(1), ponieważ wymaga tylko jednej operacji bez względu na rozmiar listy.
- Wstawianie na koniec listy (bez wskaźnika na ostatni element): O(n), ponieważ wymaga przejścia przez całą listę, aby znaleźć ostatni element.
- Usuwanie elementu z początku listy: O(1), ponieważ wymaga tylko jednej operacji bez względu na rozmiar listy.
- Operacje na drzewach binarnych:
- Wyszukiwanie elementu: O(log n), gdzie n to liczba węzłów w drzewie. Wyszukiwanie w drzewie binarnym polega na porównywaniu wartości węzłów i poruszaniu się w dół drzewa w celu znalezienia szukanego elementu.
- Wstawianie nowego elementu: O(log n), podobnie jak wyszukiwanie, ponieważ również polega na przeszukiwaniu drzewa w celu znalezienia odpowiedniego miejsca na wstawienie nowego węzła.
Big Omega
W notacji Big Omega (Ω), również znanej jako notacja dolnej granicy, ocenia się najniższą złożoność obliczeniową algorytmu. Oznacza to, że Big Omega określa górną granicę na szybkość wzrostu funkcji, mówiąc, że funkcja rośnie co najmniej tak szybko jak funkcja określona przez notację Omega.
W kontekście języka C, notacja Big Omega jest używana do opisywania dolnej granicy czasowej algorytmów. Oznacza to, że czas działania algorytmu będzie co najmniej tak szybki jak czas określony przez notację Omega, dla odpowiednio dużych rozmiarów danych wejściowych.
Przykładowo, jeśli mamy algorytm sortowania, który ma złożoność czasową Ω(n log n), oznacza to, że dla odpowiednio dużych zbiorów danych wejściowych czas działania tego algorytmu będzie co najmniej proporcjonalny do n log n, gdzie n to rozmiar danych wejściowych. Innymi słowy, dla dużych zbiorów danych ten algorytm nie będzie działał wolniej niż n log n.
Big Theta
W notacji Big Theta (Θ) określa się dokładną złożoność obliczeniową algorytmu, czyli zarówno górną, jak i dolną granicę czasową. Oznacza to, że Big Theta podaje zakres, w jakim znajduje się czas działania algorytmu dla wszystkich możliwych rozmiarów danych wejściowych.
Notacja Big Theta jest używana do określenia optymalnej lub oczekiwanej złożoności czasowej algorytmu dla różnych rozmiarów danych wejściowych. Oznacza to, że czas działania algorytmu będzie mieścił się w określonym zakresie, niezależnie od rozmiaru danych wejściowych.
Na przykład, jeśli mamy algorytm sortowania, który ma złożoność czasową Θ(n log n), oznacza to, że czas działania tego algorytmu będzie rosnął proporcjonalnie do n log n, gdzie n to rozmiar danych wejściowych. Jednocześnie, notacja Big Theta wskazuje, że czas działania tego algorytmu mieści się w określonym zakresie, który jest ograniczony zarówno od góry (przez n log n) jak i od dołu.
Przykłady
Program napisany w języku C, który jest prostą przeglądarką – sprawdza czy szukana liczba, znajduję się w bazie liczb (int numbers)
#include <cs50.h>
#include <stdio.h>
#include <string.h>
#define NUM_STRINGS 6 // Liczba elementów w tablicy strings
int main(void)
{
string strings[] = {„battleship”, „boot”, „cannon”, „iron”, „thimble”, „top hat”};
string s = get_string(„String: „);
// Sprawdzanie, czy wprowadzona liczba znajduje się w tablicy
for (int i = 0; i < NUM_STRINGS; i++)
{
if (strcmp(strings[i], s) == 0)
{
printf(„Found\n”);
return 0; // Jeśli liczba została znaleziona, przerywamy pętlę
}
}
// Jeśli liczba nie została znaleziona
printf(„Not found\n”);
return 0;
}
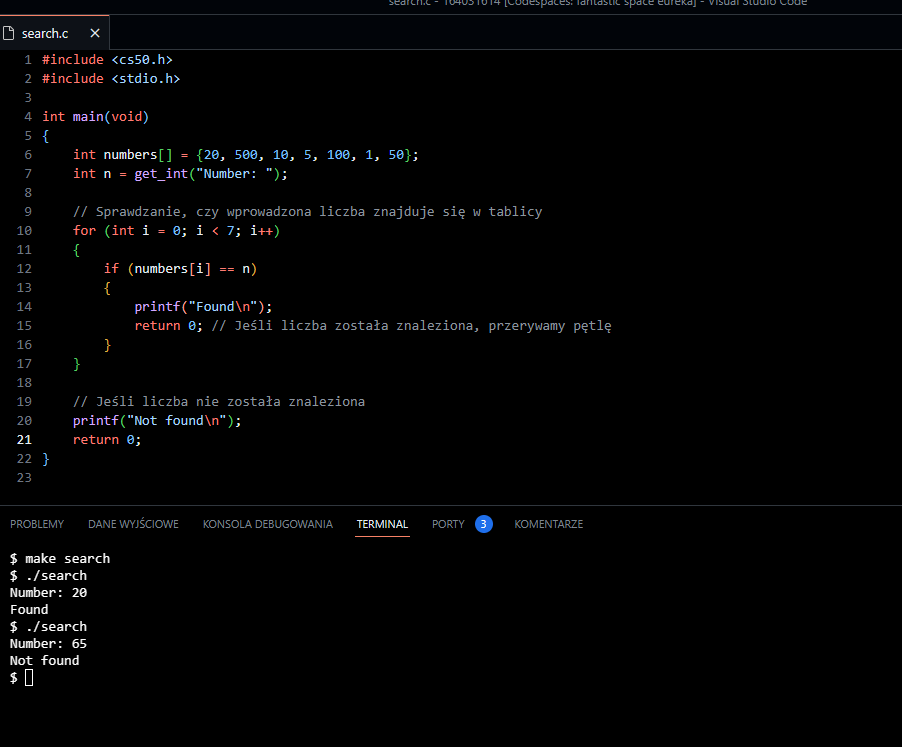
Tutaj prezentowany jest zoptymalizowany kod, który został dostosowany pod kątem przyszłych zmian. Zmieniony został zakres iteracji na wartość zmiennej n,

co sprawia, że kod staje się bardziej elastyczny i niezależny od konkretnej liczby elementów w tablicy.
Ponadto, wprowadzone zostało ulepszenie polegające na wyodrębnieniu – logiki wyszukiwania do osobnej funkcji search. Ta funkcja przyjmuje trzy argumenty: tablicę liczb, jej rozmiar oraz poszukiwaną liczbę. Zwraca ona wartość true, jeśli liczba zostaje znaleziona w tablicy, a false w przeciwnym przypadku. Dodatkowo, obliczany jest rozmiar tablicy automatycznie za pomocą operatora sizeof, co pozwala na dostosowanie się kodu do ewentualnych zmian w tablicy.
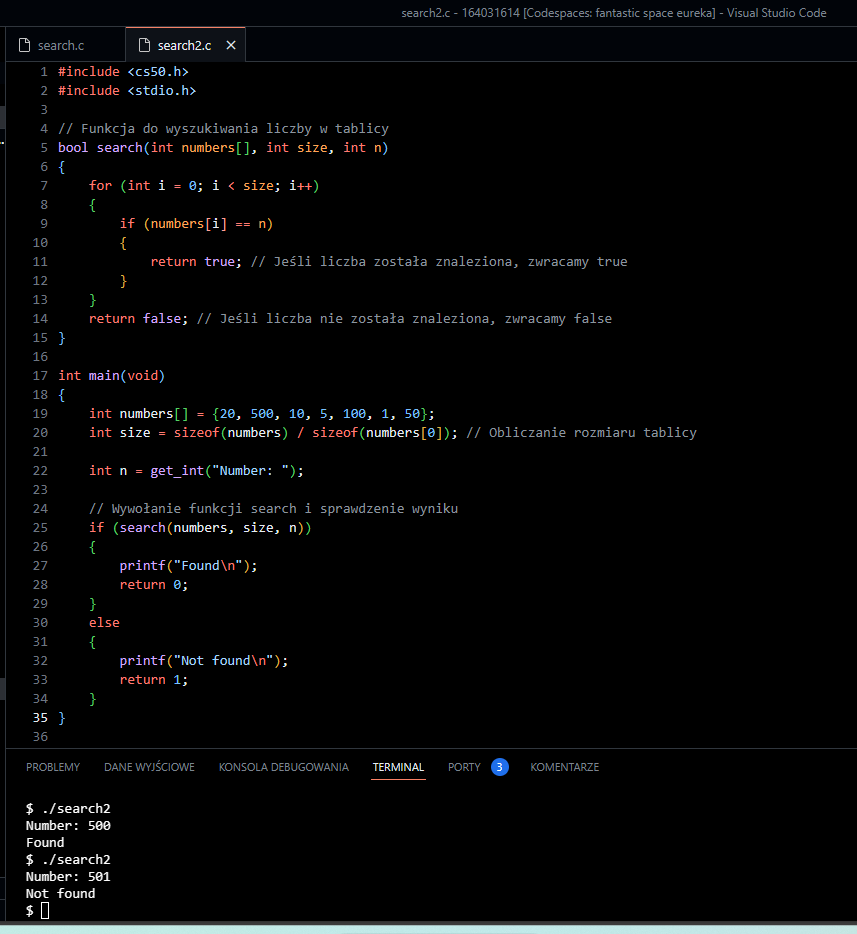
#include <cs50.h>
#include <stdio.h>
// Funkcja do wyszukiwania liczby w tablicy
bool search(int numbers[], int size, int n)
{
for (int i = 0; i < size; i++)
{
if (numbers[i] == n)
{
return true; // Jeśli liczba została znaleziona, zwracamy true
}
}
return false; // Jeśli liczba nie została znaleziona, zwracamy false
}
int main(void)
{
int numbers[] = {20, 500, 10, 5, 100, 1, 50};
int size = sizeof(numbers) / sizeof(numbers[0]); // Obliczanie rozmiaru tablicy
int n = get_int(„Number: „);
// Wywołanie funkcji search i sprawdzenie wyniku
if (search(numbers, size, n))
{
printf(„Found\n”);
return 0;
}
else
{
printf(„Not found\n”);
return 1;
}
}
Phonebook
Zakres danych tym razem to nazwy osób i przypisany numer telefonu, a zatem prosta książka telefoniczna! W przypadku uruchomienia programu po wpisaniu nazwy osoby, wyświetli się jej numer telefonu. Jeżeli program nie znajdzie – wyświetli komunikat – „not found”.

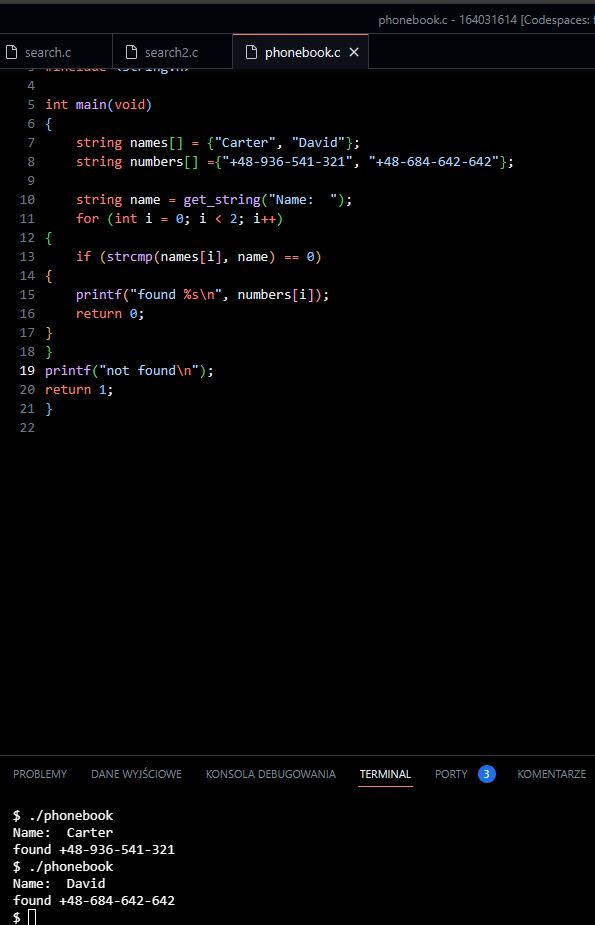
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string names[] = {„Carter”, „David”};
string numbers[] ={„+48-936-541-321”, „+48-684-642-642”};
string name = get_string(„Name: „);
for (int i = 0; i < 2; i++)
{
if (strcmp(names[i], name) == 0)
{
printf(„found %s\n”, numbers[i]);
return 0;
}
}
printf(„not found\n”);
return 1;
}



{kind=link}
{kind=link}