Wstęp
W dzisiejszym świecie programowania, Python stał się jednym z najczęściej wykorzystywanych języków, zarówno przez doświadczonych programistów, jak i tych dopiero rozpoczynających swoją przygodę z kodowaniem. Jego popularność nieustannie rośnie, dzięki czemu staje się niezbędnym narzędziem w arsenałach programistycznych na całym świecie.
Wprowadzony przez Guido van Rossum w 1991 roku, Python od samego początku wyróżniał się swoją czytelnością i przejrzystością składni, co czyniło go idealnym wyborem dla osób rozpoczynających naukę programowania. Jednakże, za tym pozornie prostym językiem kryje się potężna i wszechstronna platforma, która od lat zyskuje uznanie w wielu dziedzinach, od nauki danych po rozwój oprogramowania internetowego.
W serii wykładów „CS50” prowadzonej przez profesora Davida J. Malana na Uniwersytecie Harvard, Python odgrywa kluczową rolę jako narzędzie do nauki podstaw programowania. Wraz z dynamiką i interaktywnością tych wykładów, studenci odkrywają potencjał języka Python, zdobywając nie tylko solidne podstawy programowania, ale także umiejętność myślenia algorytmicznie i rozwiązywania problemów.
W niniejszym artykule przyjrzymy się głębiej roli, jaką odgrywa Python w kursie CS50, wydobywając kluczowe koncepcje i techniki, które uczestnicy kursu przyswajają podczas swojej podróży przez świat programowania. Poprzez analizę materiałów oraz doświadczeń studentów, przybliżymy znaczenie języka Python jako narzędzia do nauki i rozwijania umiejętności programistycznych oraz zrozumienia fundamentów informatyki.
Podstawowe funkcje Python, omawiane na wykładzie:
bool: Typ danych bool reprezentuje wartości logiczne True (prawda) lub False (fałsz). Jest używany do wyrażania warunków logicznych, takich jak w instrukcjach warunkowych (if-else) i pętlach.
x = True
y = Falsefloat: Typ danych float reprezentuje liczby zmiennoprzecinkowe. Mogą one być używane do przechowywania wartości ułamkowych lub liczb rzeczywistych.
pi = 3.14159int: Typ danych int reprezentuje liczby całkowite, czyli liczby bez części dziesiętnej. Można ich używać do przechowywania wartości całkowitych, takich jak liczby naturalne, liczby ujemne itp.
age = 25str: Typ danych str reprezentuje ciągi znaków, czyli sekwencje znaków tekstowych. Wartości typu str są umieszczane między pojedynczymi lub podwójnymi cudzysłowami.
name = "John Doe"range:
- Struktura danych range w Pythonie jest używana do generowania sekwencji liczb.
- Najczęściej jest używana w pętlach for do iteracji określoną liczbę razy.
list:
- Lista w Pythonie jest uporządkowaną i zmienialną sekwencją elementów.
- Elementy listy mogą być różnych typów danych, a lista może zawierać duplikaty.
tuple:
- Tuple (krotka) w Pythonie jest uporządkowaną i niezmienną sekwencją elementów.
- Podobnie jak listy, elementy krotki mogą być różnych typów danych, ale krotka nie może być modyfikowana po utworzeniu.
dict:
- Słownik w Pythonie jest kolekcją par klucz-wartość, w której klucze muszą być unikalne i niezmienne, a wartości mogą być dowolnego typu danych.
- Używany jest do przechowywania danych w formie klucz-wartość, co ułatwia szybkie wyszukiwanie wartości po kluczu.
set:
- Zbiór w Pythonie jest kolekcją unikalnych elementów, która nie ma określonego porządku.
- Używany jest do operacji matematycznych na zbiorach, takich jak unia, przecięcie i różnica.
Przecięcie i unia to dwie różne operacje na zbiorach, które mają zupełnie inne efekty:
Przecięcie (Intersection):
- Przecięcie dwóch zbiorów to operacja polegająca na znalezieniu wspólnych elementów, które występują zarówno w zbiorze A, jak i w zbiorze B.
- Symbolicznie oznacza się to jako A ∩ B.
- Wynikiem operacji przecięcia jest zbiór zawierający tylko te elementy, które należą do obu zbiorów jednocześnie.
A = {1, 2, 3} B = {3, 4, 5} intersection_set = A.intersection(B) print(intersection_set) # Output: {3}
Unia (Union):
- Unia dwóch zbiorów to operacja polegająca na połączeniu wszystkich elementów z obu zbiorów, eliminując duplikaty.
- Symbolicznie oznacza się to jako A ∪ B.
- Wynikiem operacji unii jest zbiór zawierający wszystkie unikalne elementy ze zbioru A i ze zbioru B.
A = {1, 2, 3} B = {3, 4, 5} union_set = A | B print(union_set) # Output: {1, 2, 3, 4, 5}
W związku z tym różnica między przecięciem a unią jest następująca:
- Przecięcie zwraca tylko te elementy, które są wspólne dla obu zbiorów, podczas gdy unia zwraca wszystkie elementy z obu zbiorów, eliminując powtarzające się.
- Wynik przecięcia będzie zawsze zawierał mniej lub tyle samo elementów niż każdy ze zbiorów wejściowych, podczas gdy wynik unii będzie zawierał co najmniej tyle samo elementów, co każdy ze zbiorów wejściowych, ale może zawierać więcej, jeśli są duplikaty w oryginalnych zbiorach.
- Różnica (ang. Difference):
Różnica dwóch zbiorów A i B to zbiór zawierający tylko te elementy, które należą do zbioru A, ale nie należą do zbioru B. Symbolicznie oznacza się to jako A – B. W Pythonie możemy użyć metodydifference()lub operatora-do wykonania operacji różnicy na dwóch zbiorach.
A = {1, 2, 3}
B = {3, 4, 5}
difference_set = A - B
print(difference_set) # Output: {1, 2}Operacje te są podstawowymi koncepcjami w teorii zbiorów i są powszechnie stosowane zarówno w matematyce, jak i w programowaniu do manipulacji danymi i rozwiązywania różnych problemów. W Pythonie są one łatwo dostępne poprzez wbudowane metody i operatory.
Dictionary
Podstawowy program np. słownik w języku Python wyglądałby następująco:
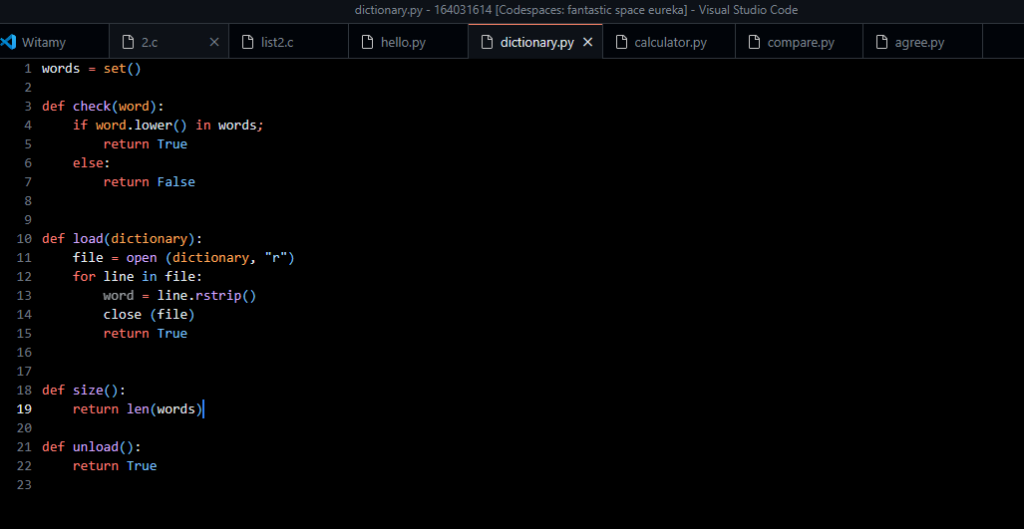
words = set()
def check(word):
if word.lower() in words;
return True
else:
return False
def load(dictionary):
file = open (dictionary, „r”)
for line in file:
word = line.rstrip()
close (file)
return True
def size():
return len(words)
def unload():
return True
Ten kod definiuje zestaw funkcji służących do zarządzania słownikiem w języku Python. Kod ten operuje na globalnym zbiorze words, który przechowuje słowa wczytane z pliku. Poniżej jest opis każdej funkcji:
words:
- Jest to zmienna globalna, która przechowuje zestaw słów.
- Jest to zmienna typu
set, co oznacza, że każde słowo wwordsbędzie unikalne.
check(word):
- Funkcja ta sprawdza, czy podane słowo znajduje się w zbiorze
words. - Jeśli słowo zostanie znalezione (bez względu na wielkość liter), funkcja zwraca
True, w przeciwnym razie zwracaFalse.
- load(dictionary):
- Funkcja ta służy do wczytywania słów z pliku i dodawania ich do zbioru
words. - Przyjmuje argument
dictionary, który jest nazwą pliku tekstowego zawierającego słowa. - Funkcja otwiera podany plik, wczytuje kolejne linie i dodaje słowa do zbioru
words.
- size():
- Funkcja ta zwraca liczbę elementów w zbiorze
wordsza pomocą funkcjilen().
- unload():
- Funkcja ta nie wykonuje rzeczywistych operacji.
- Zwraca
True, co może być sygnalem, że operacja „wypakowania” (unload) zakończyła się pomyślnie.
Calculator
Prosty program Calculator w języku Python i korzysta z funkcji get_int z modułu cs50, który jest częścią biblioteki cs50, używanej na przykład w kursach programowania na Uniwersytecie Harvard.
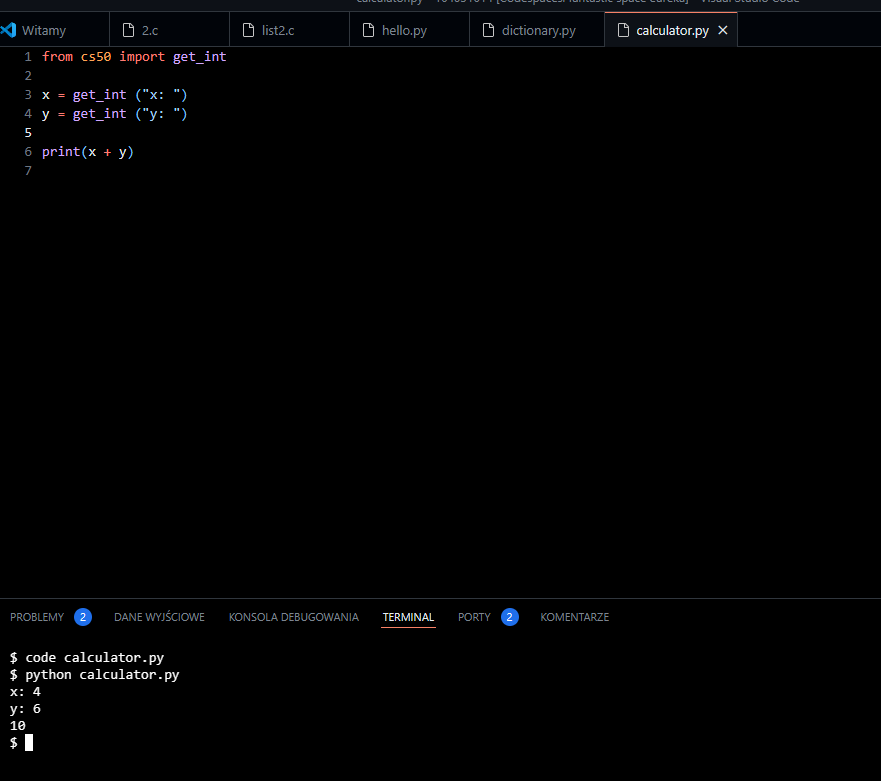
Oto opis kodu:
from cs50 import get_int:
- Ta linia importuje funkcję
get_intz modułucs50. - Moduł
cs50zawiera wiele funkcji pomocniczych, które ułatwiają pracę z wejściem/wyjściem oraz manipulacją danymi.
x = get_int(„x: „):
- Ta linia prosi użytkownika o podanie wartości dla zmiennej
xprzy użyciu funkcjiget_int. - Funkcja
get_intoczekuje od użytkownika wprowadzenia liczby całkowitej (integer). - Komunikat
"x: "wyświetlany jest użytkownikowi przed oczekiwaniem na wprowadzenie wartości.
- y = get_int(„y: „):
- Podobnie jak poprzednio, ta linia prosi użytkownika o podanie wartości dla zmiennej
yprzy użyciu funkcjiget_int. - Funkcja
get_intoczekuje od użytkownika wprowadzenia liczby całkowitej (integer). - Komunikat
"y: "wyświetlany jest użytkownikowi przed oczekiwaniem na wprowadzenie wartości.
- print(x + y):
- Ta linia dodaje zmienne
xiy, a następnie wyświetla wynik na ekranie. - Wynik dodawania jest przekazany do funkcji
print, która wyświetla go na ekranie użytkownika.
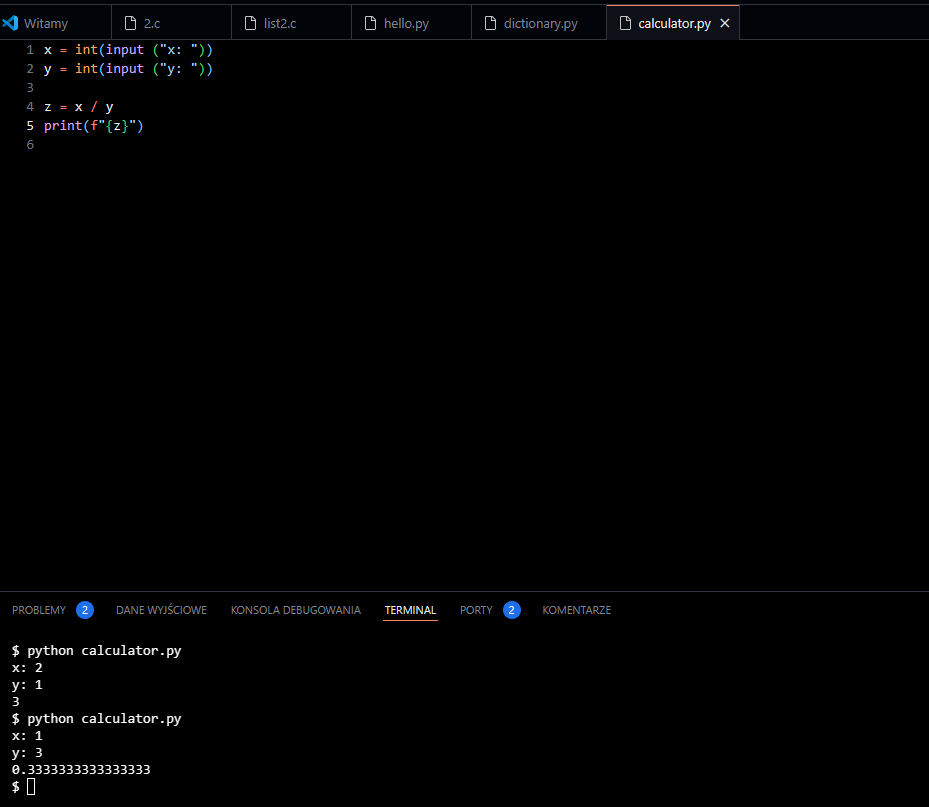
Poniżej wersja zoptymalizowana:
Możliwe zagrożenia
Floating point imprecision (niejednoznaczność zmiennoprzecinkowa) to zjawisko, które występuje w komputerach, gdy próbują one reprezentować liczby rzeczywiste za pomocą skończonej liczby bitów. W języku Python, podobnie jak w wielu innych językach programowania, zmiennoprzecinkowe wartości są reprezentowane w formacie binarnym, co może prowadzić do niedokładności w reprezentacji pewnych liczb.
W Pythonie, zmiennoprzecinkowe wartości są reprezentowane według standardu IEEE 754, który jest używany w większości współczesnych systemów komputerowych. Mimo że większość operacji na liczbach zmiennoprzecinkowych w Pythonie jest dokładna, to w niektórych przypadkach operacje arytmetyczne mogą prowadzić do niedokładnych wyników ze względu na ograniczenia reprezentacji binarnej.
Na przykład:
0.1 + 0.2Możesz się spodziewać, że wynik powyższego wyrażenia będzie równy 0.3, ale w rzeczywistości może być nieco różny:
>>> 0.1 + 0.2
0.30000000000000004To zjawisko wynika z tego, że liczby dziesiętne, takie jak 0.1 i 0.2, nie mają dokładnych reprezentacji w formacie binarnym używanym przez komputer. W rezultacie, podczas wykonywania operacji na tych liczbach, mogą pojawić się niewielkie błędy wynikające z konwersji pomiędzy reprezentacją dziesiętną a binarną.
Aby uniknąć problemów związanych z niedokładnością zmiennoprzecinkową w Pythonie, zaleca się stosowanie funkcji takich jak round() do zaokrąglania wyników operacji arytmetycznych, szczególnie w przypadku obliczeń finansowych lub innych, które wymagają wysokiej dokładności. Dodatkowo, biblioteki takie jak Decimal mogą być używane do precyzyjnych obliczeń zmiennoprzecinkowych.
Integer overflow to sytuacja, która występuje, gdy wynik operacji na liczbach całkowitych przekracza zakres, który może być przechowywany przez typ danych. W języku Python, zakres liczb całkowitych nie jest ograniczony przez liczbę bitów, co oznacza, że w teorii można tworzyć bardzo duże liczby całkowite. Python automatycznie dostosowuje rozmiar potrzebny do przechowywania liczby w pamięci, aby obsłużyć liczby całkowite o dowolnej długości.
Na przykład:
x = 2 ** 1000
print(x)Ten kod utworzy liczbę o wartości (2^{1000}), która jest znacznie większa niż maksymalna liczba całkowita, jaką można przechować w typie danych o stałym rozmiarze, np. w językach C czy Java. W Pythonie, taki kod zadziała bez problemów i wyświetli poprawny wynik.
Jednakże, w innych językach programowania, takich jak C czy Java, operacja na tak dużej liczbie całkowitej spowoduje przepełnienie (overflow) typu danych, co może prowadzić do błędów lub nieoczekiwanego zachowania programu.
W Pythonie, aby uniknąć problemów związanymi z integer overflow, nie ma potrzeby martwić się o przekroczenie zakresu liczbowego, ponieważ Python automatycznie dostosowuje się do potrzeb w zakresie pamięci. Jednakże, nadal istnieje możliwość wystąpienia innych problemów związanych z dużymi liczbami całkowitymi, takich jak wydajność i zużycie pamięci. Dlatego w przypadku manipulowania bardzo dużymi liczbami warto być świadomym tych kwestii i wybrać odpowiednią strategię implementacyjną.
ELIF – jako else if
if warunek_1:
# kod do wykonania, jeśli warunek_1 jest prawdziwy
elif warunek_2:
# kod do wykonania, jeśli warunek_2 jest prawdziwy i warunek_1 jest fałszywy
else:
# kod do wykonania, jeśli żaden z powyższych warunków nie jest spełnionyJeśli warunek_1 jest prawdziwy, wykonuje się kod w jego bloku, a reszta instrukcji „elif” i „else” jest pomijana.
Jeśli warunek_1 jest fałszywy, ale warunek_2 jest prawdziwy, wykonuje się kod w bloku „elif”, a reszta instrukcji „else” jest pomijana.
Jeśli żaden z warunków nie jest spełniony, wykonuje się kod w bloku „else”.
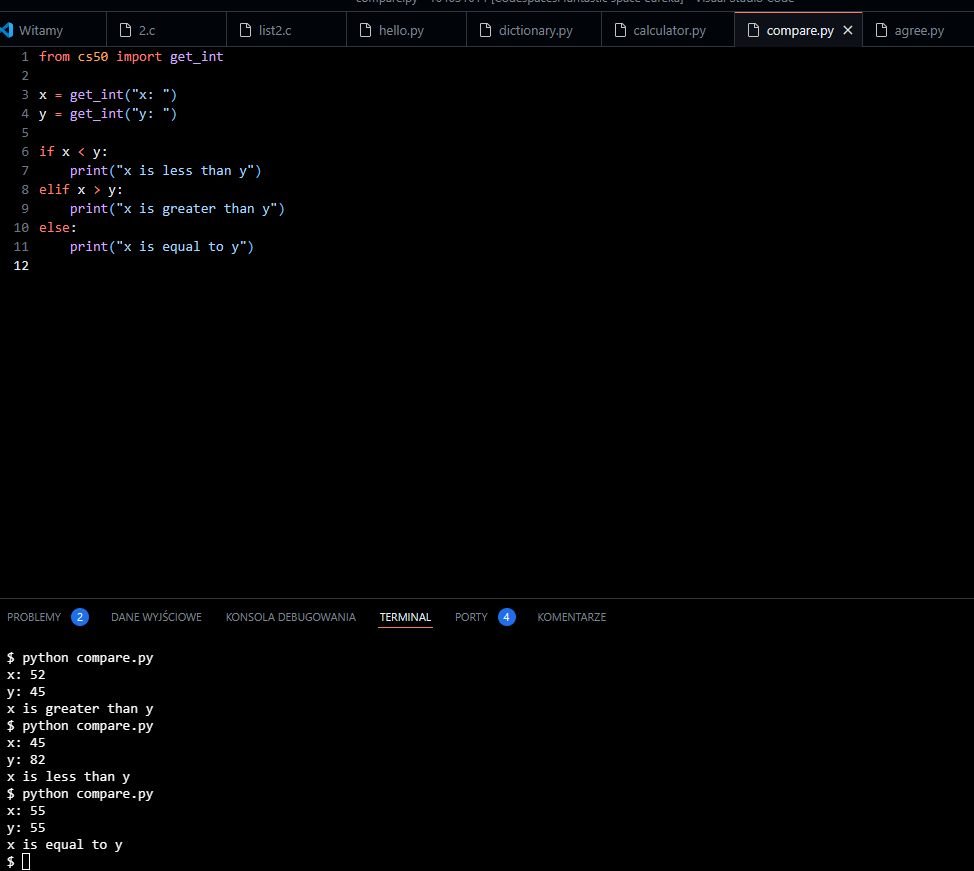
from cs50 import get_int
x = get_int(„x: „)
y = get_int(„y: „)
if x < y:
print(„x is less than y”)
elif x > y:
print(„x is greater than y”)
else:
print(„x is equal to y”)
Agree
s = input(„do you agree? „)
if s == „Y” or s == „y”:
print („Agreed.”)
elif s == „N” or s==”n”:
print („Not agreed.”)
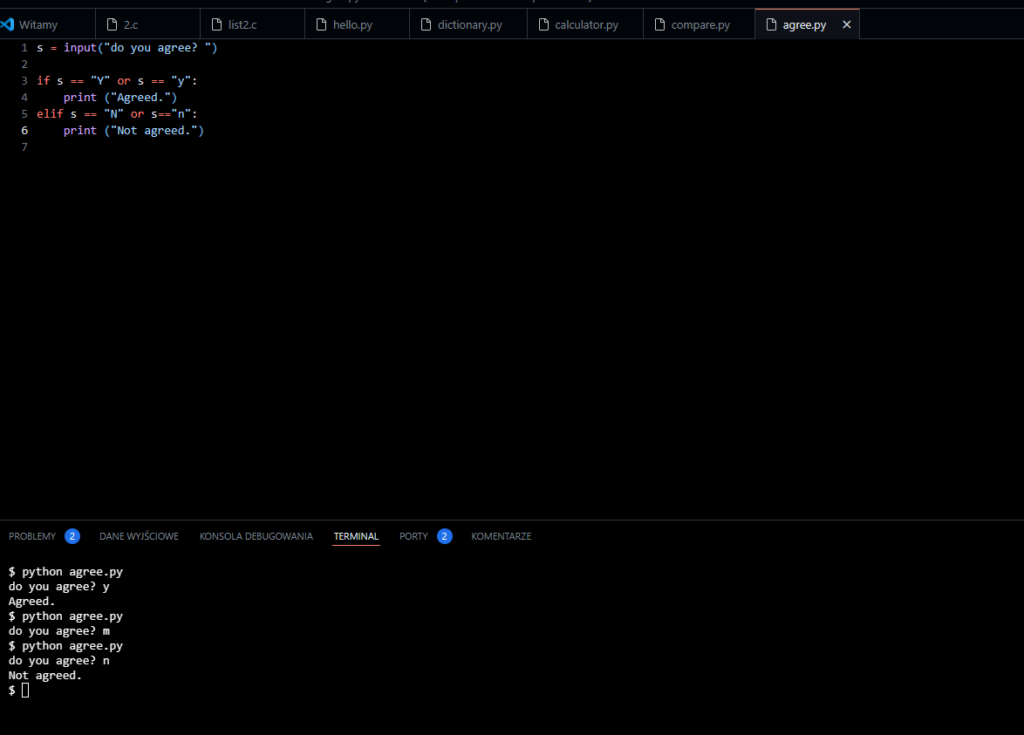
Ten kod Pythona ma następującą funkcję:
- Użytkownik jest proszony o wpisanie odpowiedzi na pytanie „do you agree? ” poprzez
input("do you agree? "). Wprowadzona odpowiedź jest przechowywana w zmiennejs. - Następnie program sprawdza, czy wprowadzona odpowiedź jest równa „Y” lub „y”. Jeśli tak, program wyświetla komunikat „Agreed.” poprzez
print("Agreed."). - Jeśli wprowadzona odpowiedź nie jest równa „Y” lub „y”, program przechodzi do sprawdzenia, czy jest równa „N” lub „n” przez instrukcję
elif s == "N" or s == "n":. Jeśli tak, program wyświetla komunikat „Not agreed.” poprzezprint("Not agreed."). - Jeśli wprowadzona odpowiedź nie jest ani „Y”/”y” ani „N”/”n”, żaden z powyższych warunków nie jest spełniony, więc nie ma wyświetlania żadnej wiadomości.
W skrócie, kod ten sprawdza, czy użytkownik zgadza się (wprowadza „Y” lub „y”) lub nie zgadza się (wprowadza „N” lub „n”) i wyświetla odpowiedni komunikat. Jeśli wprowadzona odpowiedź nie jest ani „Y”/”y” ani „N”/”n”, program nie wyświetla żadnej wiadomości.

{kind=link}